ENZO-TSC
- IMPORTANT LINKS
- Notice about exchange services and geolocation
- Introduction
- Performance
- Requirements for the User
- Security
- Download
- Algorithmic Trading and Our Model
- Q&A
IMPORTANT LINKS
- Join our Discord server for live support.
- Subscribe to our YouTube channel where we cover many important topics in greater detail.
- Download the trading client.
Notice about exchange services and geolocation
We currently support connectivity to Bybit (preferred) and Binance exchanges.
Create your Bybit or Binance account with the above links to use our service at a discounted price.
Notice that Binance has recently introduced limitations to the use of Perpetual Futures (the financial instruments that we use) to several countries, including but not limited to, Italy, UK and the Netherlands.
Before signing up for Binance, make sure that your country of residence is among those that allow to use Perpetual Futures.
Introduction
ENZO-TS is a Trading System Client for cryptocurrencies, based on proprietary technology by NEWTYPE K.K.
ENZO-TS is a software that automatically executes trades using our proprietary strategies on 19 major crypto markets.

Making a consistent profit from trading is extremely difficult. The amount of effort and dedication required, simply to stay afloat in the markets, can be overwhelming. Some may find early success, but without a strong foundation and proper risk management, luck eventually runs out, wiping out the initial gains sometimes with just a few mistakes.
We started developing the ENZO Trading System in 2018 with the goal in mind to build a system that was able to provide an alternative source of income. As it turns out, building trading strategies that are profitable with relative stability, is much harder than what it may seem initially.
Although the work never ends, we currently have what we believe is a compelling product that is worth sharing (see the FAQs on why we're currently open to external users).
ENZO-TS is a completely autonomous system that runs unattended. There's no need to configure its behavior or guess what the market will do. All trades are generated by our model on our servers, and are communicated in real-time to the client on your computer via a proprietary protocol.
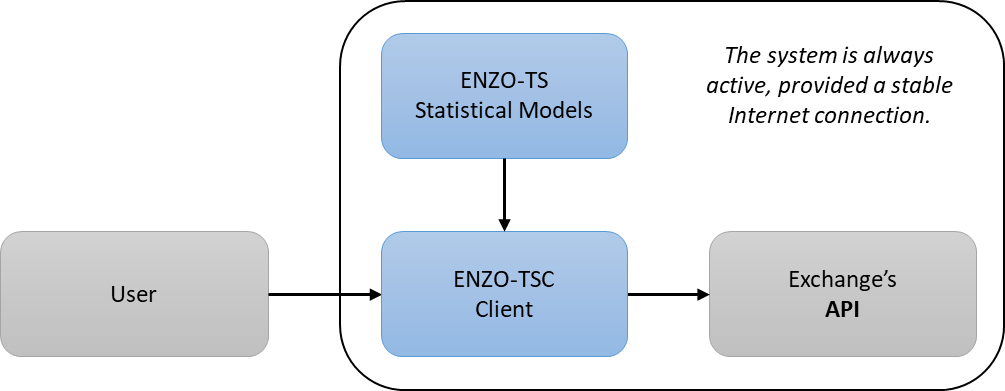
The client is connected to your exchange account via a set of API keys, allowing it to execute trades on your behalf. Your funds stay in your account and we never have any access to it.

Above is a view of the trading signals coming from our server. At any given time, an history of 60+ days worth of signals is shown, including basic performance stats and the equity curve, which displays the oscillations in profit.
Performance
Our model is the result of four years of research and development which culminated in a system that we believe is both competitive and relatively future-proof, thanks to its adaptability.
Live Performance
Live performance can be seen at the following pages:
- Reference Fund is an actual fund traded live on 19 markets and using leverage.
The Reference Fund is our "ground truth" because all trades are recorded on the exchan
Yearly Performance Reports
We started tracking our live performance since the year 2020. See the following videos for year-end reports:
- Year 2020 performance report on YouTube
- Year 2021 performance report on YouTube
About Risk Management
Risk management is embedded in the system in two ways:
- A 3.5% (unleveraged) maximum risk on each position, guarded by a stop-loss.
- A portfolio manager that spreads the fund across 19 markets, with a 25% cap on fund allocation for each market.
When considering the 25% per-market cap and the 3.5% per-position cap the final risk per position becomes less than 1%.
It should however be noted that use of leverage increases the amount of risk. For example, at 3x leverage, the maximum risk per position goes from ~1% to ~3% of the fund. Futhermore, crypto markets tend to be strongly correlated, and many times there will be more than one position taking a similar amount of risk in the same direction.
Disclaimer: it should be noted that markets evolve, and trading edges tend to deteriorate with time. So, it's important to manage the expectations and not rely on an investment of this kind for subsistence. Profits are not guaranteed and are not linear, months of loss and months of profit tend to cluster together, so, the wise investor should consider this as a medium and long term endeavor, investing only surplus money.
Requirements for the User
- A Bybit or Binance exchange account.
- A computer that can run with minimal downtime running Windows, Linux, macOS or Raspberry Pi (with Ubuntu MATE 64).
- A stable Internet connection.
Because calculations are done by our servers, the ENZO-TS application runs comfortably on low spec machines, consuming a limited amount of RAM and CPU power.
The software operates transparently and can be left unattended. It does however need to be always active and with a stable Internet connection. Depending on the market conditions, trading opportunities may happen only once per day, and the client will need to be active to act on those signals.
Security
With our solution, the funds stay in your own private account and we never have access to them.
The API key access is used by the client locally and never communicated to our servers. Furthermore, API keys can and should be limited to trading-only, so that withdrawal of funds is technically impossible for anyone that may come into possession of such keys.
Download
The client can be downloaded freely at the following link. This allows a prospective user to ensure that the software is compatible with their system.
In order to actually use the software for trading, a usage license is necessary.
Algorithmic Trading and Our Model
Man vs Machine
Perhaps the most important thing to consider is the fact that there is no single ideal way of profiting form trading. The market is composed by many players, both individuals and institutions, all trying to make a profit for themselves with their own approach. Many approaches can work at the same time, because this not a winner-takes-all kind of scenario.
The human approach to trading can be either based on special insight, based on a deeper understanding of the markets and news related to it, or it can be more methodical based on a series of indicators and rules which, if applied rigorously, can be considered as an algorithm.
The former approach is often romanticized, but it's hard to sustain and hard to quantify. A lot of cognitive bias comes into play when considering a series of facts and feelings before buying or selling an asset. The latter approach is more future-proof because it's built on a series of rules that work on hard data such as price and volume data. The latter approach can also be converted into a computer program to automate trading as well as to perform extensive testing to verify the goodness of a system.
Our approach is indeed fully quantitative. Our algorithms work purely on price and volume data, looking for a statistical edge that shows consistent profit over multiple years of historical market data.
One negative aspect of the quantitative approach, is that some of the trades may look like obviously bad choices from a human perspective. This is because a person tends to get emotionally attached to individual trades and has a general aversion to individual loss, even if it's part of a statistical system that is highly profitable as a whole.
A human trader may feel better by taking an early profit in a trade, whereas a good quantitative model might ignore that chance, sometimes to a fault, while still being the better performer at the statistical level, and therefore in the long run.
Predicting the Future
Some future events may indeed be predicted, depending on the scope of such prediction.
Modern computer models are able to predict if it will rain in the next 24 hours with a very good degree of confidence. The quality of predictions starts to falter as one hopes to guess outcomes farther into the future. This is because, with time, more randomness is added to a system, making it more difficult to predict from the data at hand.
Admittedly, markets are not direct physical entities. They can be manipulated on a whim, given a large enough amount of money, but this is also something that can become part of a model. One may not predict when something happens in the time domain, but a statistical model can still leverage knowledge in the frequency domain (read: chance of occurrence).
Quick Overview of the Model
The model is based on an ensemble of algorithms operating on multiple markets and balanced by a dynamic portfolio management system. No single algorithm on a single market is responsible for the overall performance. This focus on a multitude of markets makes the system inherently more stable and more reliable, because
Each algorithm branches into a series of variations, bringing the whole range of possible combinations into the hundreds, all of which are actively simulated also during live trading. Selection of the specific algorithm to be used for live trading is performed via machine learning. Because our software is written in high performance C++, we have more power and flexibility at our disposal when it comes to techniques that can be applied.
The algorithms are based on custom indicators of our design. These indicators are based on a series techniques, often simple and easy to compute, but sometimes more advanced and requiring heavier computations.

Above is an example of our "MMatch" indicator, utilizing self-adapting affine transformations to extrapolate a potential market prediction
Q&A
Q: Why are you sharing your system, if it is profitable?
A: Because it takes money to make money.
We are a small, self-funded, start-up with limited capital to invest. Trading can be very profitable, but returns are volatile and can bring multiple months of drawdown.
Income from licensing, while not as profitable in the long term, is more stable and it works as an hedge against the instability of trading.
Licensing also gives us exposure in the field and the opportunity to study market behavior with larger capital at play, something that can't easily be simulated otherwise.
Lastly, we don't aim to become a large-scale consumer solution and we reserve the right to stop accepting new users once we'll determine that our strategies have reached the point beyond which additional volume would become counterproductive to us and the existing users.
Q: How is this different from other consumer solutions?
A: Large-scale consumer solutions cannot, by definition, provide an ideal solution to all of their users. For this reason, automated trading platforms expect the user to tweak their own strategy or to copy strategies from many possible ones published by random strangers.
While it can be educative to try to develop your own strategy, it's extremely difficult and it can take years to come up with something that can work consistently.
When it comes to social-trading, the best strategies available at any given time are those that have done good up to that point. This is a process of selection that is likely the result of luck rather than actual insight.
Imagine a room with a 10,000 monkeys executing random trades. It's likely that at least one of them will do well enough for a while. This doesn't mean that the monkey is a good trader, rather that 1 in 10,000 monkeys was lucky enough to make the cut.
This example is an obvious exaggeration, but it makes the point about the hidden danger of survivorship bias.
What we offer is access to a complete trading system and a set of strategies that are continuously improved and tested for their predictive abilities, rather than being a lucky draw out of many random signals.
Q: Are you doing HFT such as arbitrage?
A: Some of our techniques rely on high-frequency data to catch sudden price movements, however the system still performs a relatively small amount of trades.
When it comes to actual HFT, there is a series of fundamental issues that makes it not suitable for most. Timing is very important, which translates into the need to improve the physical location of the trading system itself. Arbitrage is also difficult to test off-line in a simulation (read: without losing real money), because it's a dynamic kind of trading based on real-time action and reaction, while historical data at larger time frames can be considered static for practical purposes of testing.
The fundamental concept of arbitrage is also simple enough for occasional edges to quickly evaporate. Another issue is that fees on crypto exchanges make it prohibitive to truly execute a large number of trades without instantly losing profit on fees alone.
Q: When will you add support for other cryptocurrencies
A: We currently support 19 crypto markets, although the system is capable to adapt to more markets. However our system relies on some machine learning techniques that require a minimum of historical data. For this reason, new markets with limited history are not good candidates. We plan nonetheless to expand the system to be more flexible, but this is currently not a high priority.
Q: When will you support other exchanges?
A: Adding new exchanges is in the plans. If you'd like to see a particular exchange server supported, please let us know.